안녕하세요, Allan입니다.
이번 포스팅을 보시기 전에 스테이블 디퓨전의 원리 시리즈를 처음부터 보고 오시는 것을 추천드립니다.
Diffusion 모델 - 쉽게 이해하는 스테이블 디퓨전 원리1
Latent Diffusion 모델 - 쉽게 이해하는 스테이블 디퓨전 원리2
이번 포스팅에서는 text prompt가 Latent Diffusion 모델에서 이미지를 생성할 때 어떻게 관여하는 지 알아보도록 하겠습니다.
Ⅰ. Conditioning
앞의 두 포스팅에서 설명드린 과정에 따르면 우리는 생성되는 이미지를 통제할 수 없게 됩니다.
단지 Diffusion 모델, 혹은 Latent Diffusion 모델의 forward diffuison 방식과 reverse diffusion 방식에 대해서만 알아보았기 때문입니다.
이미지 생성에 text prompt가 관여하기 위해서 필요한 것이 Conditioning입니다.
Conditioning은 reverse diffusion 과정에서 noise predictor가 추정된 노이즈 혹은 Latent 노이즈를 제거하고 우리가 원하는 이미지가 될 수 있도록 노이즈 예측기를 조정하는 것을 의미합니다.
Ⅱ. Text Conditioning
본격적으로 text prompt가 Conditioning 과정을 거쳐 noise predictor로 공급되는 방식에 대해서 알아보도록 하겠습니다.
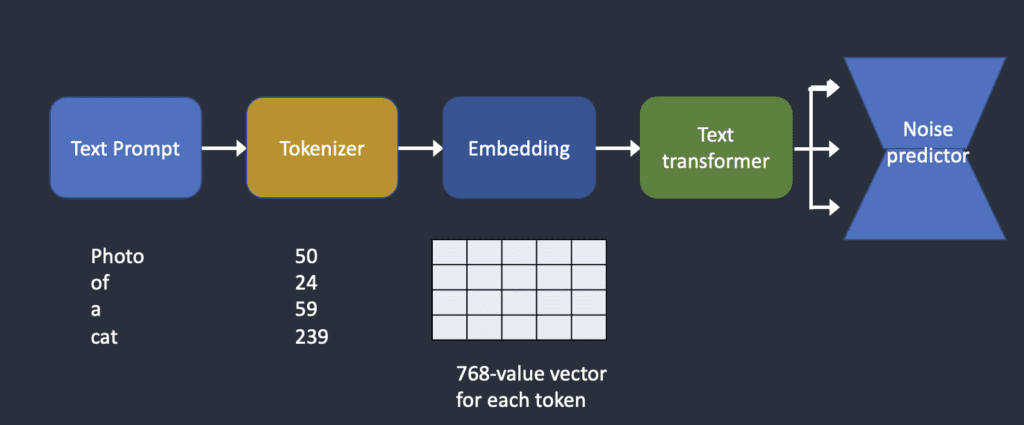
위의 이미지를 통해 먼저 간단하게 설명드리겠습니다.
- 텍스트 프롬프트는 토크나이저를 통해 각 토큰으로 분리 된 후 컴퓨터에서 인식할 수 있는 숫자로 변경됩니다.
- 숫자로 변환된 토큰은 embedding으로 변환됩니다.
- embedding은 Text transformer를 거쳐 noise predictor로 공급됩니다.
그럼 각 단계에 대한 자세한 설명을 드려보도록 하겠습니다.
Ⅱ-1. Tokenizer
토크나이저는 우리가 입력한 텍스트 프롬프트를 컴퓨터가 이해할 수 있는 숫자로 변환해주는 역할을 합니다.
스테이블 디퓨전은 Clip 토크나이저를 사용합니다.
Clip은 Open AI가 개발한 딥러닝 모델로 이미지에 대한 텍스트 설명을 생성하는 모델입니다.
변환 과정은 다음과 같습니다.
- 텍스트 프롬프트를 토큰 단위로 분리한다.
- 분리된 토큰을 컴퓨터가 이해할 수 있도록 변환한다.
우리가 알아야 할 과정은 텍스트 프롬프트가 토큰 단위로 분리되는 과정입니다. 이 과정을 이해하면 우리는 스테이블 디퓨전이 더 잘 이해할 수 있도록 프롬프트를 작성할 수 있기 때문입니다.
토크나이저는 훈련 과정에서 본 단어만 토큰화 할 수 있습니다.
예를 들면, Clip 모델에 dream과 beach는 있지만 dreambeach는 없다고 가정해 보겠습니다.
토크나이저는 dreambeach라는 프롬프트를 받게 되면 dream과 beach두 개의 토큰으로 분리합니다.
즉, 100% 하나의 단어를 하나의 토큰으로 변환하지 않는다는 것입니다.
(대부분의 경우에 하나의 단어를 하나의 토큰으로 변환합니다.)
webui에서 확인해 보면 프롬프트 우측에 최대 토큰 수 75가 표시되어 있는 것을 확인할 수 있습니다.
이는 스테이블 디퓨전에서 이해할 수 있는 토큰 수를 의미합니다.
물론 토큰 수가 75가 넘어가도 프롬프트를 작성할 수 있지만, 프롬프트 이해도가 떨어질 수 있다는 단점이 존재합니다.
따라서, 되도록 프롬프트는 75 토큰을 넘어가지 않도록 작성하는 것이 좋습니다.
Ⅱ-2. Embedding
텍스트 프롬프트는 토크나이저에 의해 토큰으로 변환되고 토큰은 Embedding이라는 벡터값으로 변환됩니다.
임베딩은 키워드를 스타일로 변환하기 위해 존재합니다.
의미가 비슷한 단어일수록 임베딩 값은 유사합니다.
예를 들면 man, gentleman, guy 등은 비슷한 의미를 가지기 때문에 유사한 임베딩 값을 가지게 됩니다.
임베딩은 키워드로 스타일 혹은 개체를 구현할 수 있는 역할을 합니다.
Ⅱ-3. U-Net (Noise predictor)
임베딩은 text transformer를 통해 한번 더 처리된 후 U-Net으로 공급됩니다.
U-net은 text prompt와 이미지가 만나는 공간입니다.
Latent Diffusion 모델의 reverse diffusion 과정을 생각해 보겠습니다.
reverse diffusion 과정에서 noise predictor는 추정된 노이즈를 제거하고 이미지에 새로운 것을 제공합니다.
text transformer에서 처리된 임베딩은 rever diffusion 과정에 있는 이미지가 우리가 입력한 텍스트 프롬프트에 따라 생성될 수 있도록 noise predictor를 조정합니다.
Ⅲ. 마무리
이번 포스팅에서는 텍스트 프롬프트가 이미지에 관여하는 방법에 대해서 알아보았습니다.
핵심만 요약하자면 다음과 같습니다.
- 텍스트 프롬프트는 토크나이저를 통해 토큰화 된 후 임베딩으로 변환된다.
- 임베딩은 text transformer에서 한번 더 처리된 후 U-net에서 이미지와 만난다.
다음 포스팅에서는 text-to-image의 전체적이 과정에 대해서 설명해 드리도록 하겠습니다.


